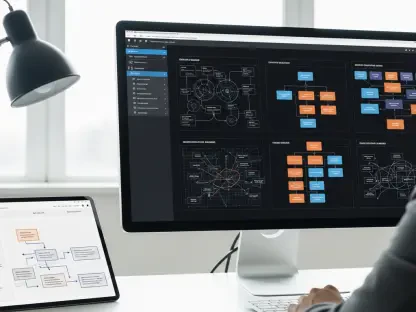
Engineering teams often discover that the most sophisticated reactive autoscaling policies are no match for a sudden tidal wave of traffic that arrives in a matter of seconds. Modern digital infrastructure faces a unique threat: the flash crowd. Unlike organic growth, these events—such as product

High-performance software organizations have come to realize that the most persistent bottlenecks in their delivery pipelines are usually rooted in human communication rather than in server configurations or coding errors. This realization marks a fundamental shift in how businesses approach

The global landscape for alternative asset management has undergone a profound transformation as institutional investors increasingly pivot toward private markets to secure reliable, long-term yields. Within this shifting environment, Brookfield Asset Management has emerged as a dominant force,

The global real estate market is currently navigating a period of unprecedented structural change as institutional investors grapple with the dual challenges of interest rate stabilization and the urgent necessity of decarbonizing aging portfolios. This shift has triggered a massive wave of

The transition from massive centralized cloud infrastructures to specialized local language models represents one of the most significant shifts in software engineering within recent memory. This evolution allows developers to bypass the latency, cost, and privacy concerns that often plague

The rapid transition from experimental large language model demonstrations to hardened enterprise-grade autonomous systems has fundamentally shifted the focus of developers from mere output generation to the rigorous verification of every internal decision-making step. As organizations deploy