
The rapid expansion of Large Language Model capabilities has fundamentally altered the economics of software engineering, where the verbosity of source code now directly translates into tangible operational expenses. As developers increasingly rely on automated agents for code generation, refactoring, and maintenance, the syntactic overhead of high-level programming languages has become a critical factor in cloud computing costs. While the industry has long championed the safety and maintainability benefits of static typing, the financial implications of sending verbose type definitions through API-driven inference engines remain largely unexamined by many development teams. Every extra character and punctuation mark processed by an LLM contributes to the total token count, which in turn dictates the monthly billing for organizations utilizing these advanced systems. In this landscape, the distinction between a concise script and a heavily annotated codebase is no longer just a matter of developer preference or stylistic choice but a measurable impact on the corporate bottom line. This paradigm shift necessitates a more granular understanding of how specific programming languages interact with the tokenizers that power contemporary artificial intelligence. By examining the relationship between syntax and token density, engineers can make informed decisions that balance the necessity of code safety with the practical reality of budget constraints in the modern tech ecosystem.
1. The Research Methodology: Quantifying Logic Through Systematic Analysis
To determine how different coding styles impact API costs, the study followed a rigorous set of procedures designed to isolate the impact of syntax on overall token consumption. The first step was to develop identical logic across all subjects, ensuring that each programming task was coded in five different languages including JavaScript, TypeScript, CoffeeScript, Civet, and ZeroLang using the same underlying algorithmic approach. By keeping the core functionality consistent, the researchers were able to eliminate algorithmic complexity as a variable, focusing purely on how each language represents that logic through its unique syntax. Furthermore, the team made a conscious effort to utilize idiomatic patterns throughout the process. The code was written naturally rather than being “golfed” or artificially compressed to ensure a fair comparison of standard practices that a typical professional developer would use in a production environment. This approach provided a realistic baseline for how production-grade code interacts with the language models commonly used in 2026.
The second phase of the investigation focused on turning these code samples into quantifiable data points that reflect actual operational costs. The researchers chose to quantify volume through tokenization, leveraging the modern standard for text processing in artificial intelligence. Specifically, the researchers used the tiktoken library, utilizing the cl100k_base encoding, to count how many tokens each snippet consumed when prepared for an LLM request. This method provided a precise numerical value for the “Syntax Tax” by allowing for a direct comparison of the results. The study measured the extra cost incurred by punctuation, such as braces and semicolons, as well as the dense static type annotations required by more verbose languages. By comparing these figures across the different language samples, the analysis revealed the hidden price of syntactic safety. This data-driven approach moved the conversation from anecdotal evidence about code “cleanliness” to a concrete understanding of how punctuation and type declarations inflate the operational budget of AI-integrated development pipelines.
2. Strategy for Deliberate Type Usage: Balancing Safety and Efficiency
To balance the benefits of type safety with the need for token efficiency, developers should follow a strategy that prioritizes high-impact annotations while stripping away redundant boilerplate. A primary tactic in this balanced approach is to apply types to external interfaces exclusively. By using explicit annotations for public function signatures, exported APIs, and module boundaries, engineers can maintain clarity for both humans and AI without inflating the entire file size. These boundaries are the most critical points for documentation and error prevention, providing enough context for an LLM to understand the data flow without requiring a play-by-play description of every internal transition. This ensures that the essential structure of the software remains intact and well-documented, allowing the AI to generate accurate code based on clear interface definitions while keeping the overall token count manageable during long-running sessions or complex refactoring tasks.
Beyond the boundaries of external modules, developers can achieve significant savings by trusting the capabilities of modern language processors. A highly effective second step is to allow the compiler to deduce internal logic rather than manually defining every type. This means developers should avoid redundant annotations on local variables where the system can already determine the type through inference. Modern compilers and language servers are exceptionally proficient at tracking types through a function’s body, and LLMs are equally capable of following these logical threads without explicit help. Additionally, it is often wise to opt for basic JavaScript for AI-centric scripts. When writing prompt builders or throwaway generators intended primarily for LLM consumption, developers should favor leaner, untyped syntax to minimize overhead. This tailored approach allows for the high-speed, low-cost generation of auxiliary scripts where the long-term maintainability of TypeScript is less critical than the immediate efficiency of the AI interaction.
3. How to Measure Your Own Token Usage: Establishing a Cost Baseline
You can calculate the “type tax” on your own codebase by following several straightforward technical steps to gain transparency into your token consumption patterns. The first requirement is to set up the necessary library within your local development environment to mirror the processing done by the model providers. This involves installing the tokenizer by running pip install tiktoken in your terminal. Once the library is active, the next step is to prepare a measurement script that can automate the counting process across multiple files. Developers should create a short Python file that imports tiktoken, loads the specific source file intended for analysis, and prints the length of the encoded text. This script serves as a localized version of the billing engines used by major AI providers, giving the team immediate feedback on the potential cost of their code before it is even sent to the cloud.
After the measurement infrastructure is in place, the process shifts toward iterative optimization and comparison. To start, you must establish a baseline by executing the script on your original TypeScript or JavaScript file to see the initial token count in its current state. Once this figure is recorded, the optimization phase begins by making targeted changes to the source code. Developers should remove unnecessary declarations and strip out the type annotations that the compiler is capable of inferring on its own while keeping essential public signatures for structural integrity. The final step is to perform a second measurement by running the script again on the cleaned file to see the percentage of tokens saved. This comparison provides a clear metric for the efficiency gains achieved through syntax optimization. By repeatedly applying this cycle to different modules, organizations can develop internal standards for “LLM-friendly” code that reduces costs without compromising the reliability of the application.
4. Key Findings and Cost Comparisons: The Impact of Syntactic Density
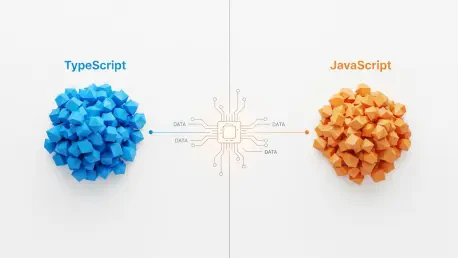
The analysis resulted in a clear hierarchy of efficiency that highlights the massive disparity between different programming syntaxes when processed by tokenizers. At the top of the efficiency list sat ZeroLang, which consumed only 231 tokens. This language was designed specifically for AI agents with minimal punctuation, making it the most cost-effective option for machine-to-machine communication. Following closely behind was CoffeeScript at 239 tokens, which maintained high efficiency due to its reliance on indentation rather than heavy braces. JavaScript served as the middle-ground baseline for standard web development, coming in at 287 tokens. While widely used, JavaScript was already notably slowed down by punctuation density compared to its more minimalist counterparts. These findings suggest that the traditional web stack, while robust, carries an inherent “token weight” that adds up significantly as projects scale in the age of generative intelligence.
The most expensive end of the spectrum featured languages that prioritize explicit structure and safety over brevity. Civet occupied a middle ground at 320 tokens, offering a terse syntax but quickly losing its efficiency once TypeScript-style types were added to the mix. Ultimately, TypeScript was the most expensive option in the study, totaling 377 tokens and costing roughly 31% more than plain JavaScript due to heavy type annotations. The research eventually demonstrated that the most effective path forward involved a tiered approach to language selection based on the specific operational environment. Teams discovered that while TypeScript was indispensable for complex logic and multi-developer collaboration, the financial premium was high enough to justify stripping types during the LLM inference phase. Developers eventually implemented automated preprocessing steps to “de-type” code before sending it to AI agents, which effectively preserved the benefits of static safety while securing the cost-effectiveness of leaner syntax.







