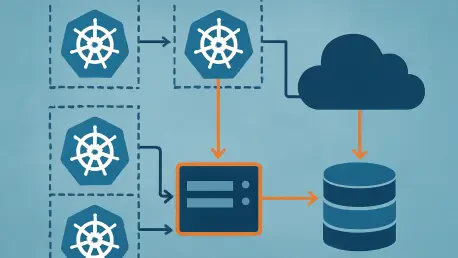

The relentless pursuit of horizontal scalability has inadvertently created a massive context gap where stateless application layers often lose track of the very data they just modified. This architectural friction between ephemeral Kubernetes pods and persistent cloud databases has become the defining technical bottleneck for high-scale microservice deployments. As developers push for greater agility, the traditional methods of managing user state have collapsed under the weight of distributed complexity, necessitating a more sophisticated approach to session coordination. This review evaluates the current state of decentralized state management, focusing on how organizations are finally bridging the divide between stateless compute and stateful storage.
The primary challenge lies in the nature of modern orchestration. When a system scales horizontally, a user’s request may be handled by one instance for a write operation and an entirely different instance for the subsequent read. In a world where databases like Azure Cosmos DB rely on session tokens to guarantee consistency, this “hop” between instances often results in the second pod lacking the necessary context to retrieve the most recent data. The resulting “stale read” is not a failure of the database itself, but a byproduct of the infrastructure’s inability to propagate session metadata across a fluid environment.
The Architecture of Distributed State Management
Modern cloud architecture has undergone a fundamental shift from localized state to decoupled coordination. In the past, session data was often stored in-memory on a specific server, but this “sticky” approach creates massive hot spots and prevents the system from scaling effectively. As organizations move toward Kubernetes and serverless functions, the industry has realized that session context must exist independently of the compute resource. This realization has led to the rise of specialized coordination layers that manage the “who, what, and when” of data transactions without being tethered to a single virtual machine or container.
This decoupled approach requires a rethink of the relationship between the application and the database. Rather than treating the database as a black box that handles all consistency logic, developers are now building a “coordination fabric” that sits between the layers. This fabric is responsible for capturing the transient metadata generated by database operations and making it available to any node in the cluster instantly. By separating the durable data from the session state, engineers can achieve the holy grail of cloud computing: a system that is both perfectly stateless in its execution and perfectly stateful in its outcomes.
Moreover, this architectural evolution is driven by the need for lower latency in globalized environments. As users demand sub-second response times regardless of their geographic location, the cost of global database locking becomes prohibitive. Distributed session coordination offers a middle ground, allowing for localized performance with global consistency guarantees. It represents a move away from heavy, monolithic locking mechanisms and toward a more agile, metadata-driven model that reflects the dynamic nature of 2026’s digital landscape.
Key Mechanisms for Maintaining Session Consistency
The effectiveness of any distributed system depends on its ability to synchronize state across multiple nodes without introducing significant overhead. For session coordination, this typically involves a two-pronged strategy: intelligent brokerage of metadata and the optimization of how data is actually modified. These mechanisms work in tandem to ensure that the system remains responsive even as the volume of requests grows. Without these tools, the complexity of managing thousands of concurrent sessions would lead to catastrophic data drift and a degraded user experience.
Session Token Brokerage via Redis
The most prominent implementation of this coordination involves using a high-performance, in-memory store like Redis to act as a centralized broker for session tokens. When an application pod writes a document to a distributed database, the database returns a session token—a unique identifier that represents that specific point in time for that specific session. In a naive implementation, this token is lost if the next request goes to a different pod. However, by immediately pushing this token into a shared Redis cache, the system ensures that any other pod in the cluster can retrieve it before performing a read.
This brokerage pattern is unique because it treats Redis not as a traditional data cache, but as a coordination bus. The information stored is ephemeral and lightweight, meaning it does not burden the system with massive storage requirements. By fetching the latest token from Redis before querying the primary database, the application can “force” the database to provide the most recent version of a document. This achieves a “read-your-own-writes” guarantee across the entire Kubernetes cluster, effectively masking the stateless nature of the underlying pods from the end-user.
Optimized Data Modification with Partial Updates
Beyond simple token management, the shift toward partial document updates has transformed how session state is maintained. Traditionally, updating a user session meant retrieving a large JSON document, modifying a single field, and then replacing the entire document in the database. This approach is not only expensive in terms of Request Units (RUs) but also increases the risk of “lost updates” if two pods attempt to modify the same document simultaneously. The transition toward operations like the Cosmos DB PATCH command has fundamentally changed this dynamic.
By sending only the specific change—such as adding an item to a shopping cart or updating a timestamp—the coordination layer reduces the payload size and the processing power required by the database. This efficiency is critical for maintaining session integrity in high-traffic scenarios. Partial updates allow the system to handle higher throughput with less contention, as the database can merge these specific changes more intelligently than it could with full document replacements. This granular control is a cornerstone of modern distributed systems, ensuring that session coordination remains fast and cost-effective.
Emerging Trends in Decentralized Coordination
The technological landscape is currently moving toward more autonomous, non-blocking coordination strategies that reduce the manual burden on developers. We are seeing a significant move away from custom-coded coordination logic toward “sidecar” patterns within service meshes. In these environments, the sidecar automatically intercepts database responses, extracts the session tokens, and synchronizes them across the mesh without the application logic ever being aware of the process. This abstraction allows developers to focus on business features rather than the plumbing of distributed consistency.
Furthermore, there is an increasing trend toward multi-layered caching strategies that prioritize consistency based on the specific needs of the transaction. Not all data requires strict session coordination; for example, a user’s profile picture might be allowed to be “eventually consistent,” while their bank balance requires immediate synchronization. Intelligent coordination layers are now being designed to distinguish between these data types, applying high-performance brokerage only where it is strictly necessary. This selective coordination maximizes throughput while maintaining the integrity of critical business processes.
Real-World Applications and Industrial Deployments
The impact of distributed session coordination is most visible in industries where the cost of data inconsistency is high. In the e-commerce sector, the technology has solved the persistent problem of “ghost” items in shopping carts, where a user adds an item but then sees an empty cart after a page refresh due to pod switching. By using a centralized token broker, retailers ensure a seamless experience even during massive traffic spikes like Black Friday, where horizontal scaling is most aggressive.
In the financial services industry, the stakes are even higher. Banking platforms built on microservices use these coordination patterns to maintain strict transaction contexts across different services. When a user moves money between accounts, the coordination layer ensures that every service involved in the transaction sees the same state of the ledger, regardless of which physical server is processing the request. This has allowed banks to migrate away from expensive, inflexible legacy mainframes toward more resilient and scalable cloud-native architectures without sacrificing the consistency their customers expect.
Technical Hurdles and Mitigation Strategies
Despite the clear advantages, implementing a distributed coordination layer is not without its risks. The most significant challenge is the introduction of a new dependency: if the coordination broker (like Redis) goes down, the entire consistency model can collapse. To mitigate this, modern architectures utilize “graceful degradation” strategies. In these setups, if the coordination layer is unavailable, the system automatically falls back to the database’s default consistency level. While this might lead to an occasional stale read, it prevents a total system outage, prioritizing availability over perfect consistency in emergency scenarios.
Another major hurdle is the physical limitation of speed—regional latency. In multi-region deployments, syncing session tokens across the globe can introduce a bottleneck that negates the performance benefits of a distributed database. The industry has responded by implementing “region-aware” coordination, where session state is synchronized primarily within a geographic cluster, with asynchronous updates sent to distant regions. This recognizes that a user is unlikely to hop from a server in New York to a server in Tokyo in the span of a single session, allowing for optimized performance within the local context.
Future Trajectory of Distributed Coordination
The next frontier for this technology is the deeper integration of the data layer with the orchestration layer. We are moving toward a future where the database and the container orchestrator share a unified control plane. In this model, Kubernetes would be “aware” of the database’s session state and could route traffic to specific pods that already hold the necessary context, or the database could automatically push session tokens to the pods that are most likely to handle the next request. This proactive coordination will further reduce the latency associated with manual metadata brokerage.
We also anticipate the rise of “self-healing” state management, where machine learning models predict the consistency needs of a session in real-time. If a system detects a high probability of a conflict or a stale read, it could automatically tighten the consistency requirements for that specific user session while keeping the rest of the system in a high-performance, relaxed state. This evolution will likely lead to architectures that are not just scalable, but also “intelligent,” adjusting their coordination strategies on the fly to balance the competing demands of cost, speed, and correctness.
Summary of Technological Impact
Distributed session coordination has effectively solved the paradox of maintaining a persistent user experience within a fundamentally transient infrastructure. By decoupling session metadata from the compute layer and utilizing intelligent brokerage mechanisms, organizations have successfully bridged the gap that once made stateless microservices risky for complex data operations. The transition from full document replacement to more efficient partial updates further solidified the viability of this approach, proving that performance and consistency are not mutually exclusive. These advancements allowed for the creation of more resilient global systems that handled high-stakes transactions with the same ease as simple data lookups.
The industry moved toward a more nuanced understanding of consistency, where the focus shifted from absolute database rules to a more flexible, application-led coordination model. This change reduced the operational burden on engineers and paved the way for the sophisticated multi-region deployments we see today. Ultimately, the adoption of these coordination patterns transformed the cloud-native landscape, making it possible to build applications that were both highly responsive and impeccably accurate. The lessons learned from this architectural shift have now become the foundation for the next generation of autonomous, self-optimizing distributed systems.







