
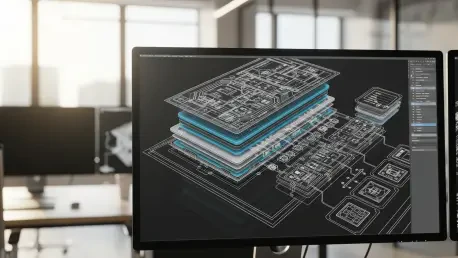
The relentless pursuit of rapid deployment frequently blinds modern software engineering teams to the catastrophic structural fragilities quietly accumulating beneath the surface of their feature backlogs. While traditional frameworks emphasize speed, the most successful organizations in the

The once-hallowed image of a lone developer hunched over a glowing screen at midnight, churning out thousands of lines of syntax in isolation, has been replaced by a new reality where engineering success depends on high-level orchestration and strategic foresight. In the current landscape,

The rapid acceleration of digital transformation has forced global enterprises to treat cloud migration not as a secondary IT project but as a foundational pillar for operational resilience and competitive survival. In the high-stakes world of modern finance and healthcare, a single hour of

The difference between a high-performing engineering culture and a stagnant one often comes down to the psychological weight of the "deploy" button. When a single code change requires a sixty-minute wait for validation and shipping, developers naturally stop iterating and start batching, which

The global business landscape reached a pivotal turning point in March 2026 when the Project Management Institute Agile Alliance unveiled the Manifesto for Enterprise Agility in Lagos, Nigeria, marking the twenty-fifth anniversary of the foundational Agile Software Development guidelines. This new

Modern market dynamics have reached a level of volatility where traditional corporate structures are no longer just inefficient; they have become active liabilities for global sustainability and growth. While nearly every executive acknowledges that rapid business model transformation is the only







