
The silent failure of a single third-party payment API once forced an unsuspecting engineering team to confront a staggering $180,000 labor bill just to keep their basic operations afloat. This massive financial drain was not caused by a catastrophic security breach or a total server meltdown, but rather by the subtle “spaghetti” of tight coupling where seven separate microservices were directly tethered to an external vendor’s specific data format. When that vendor announced a mandatory deprecation of their legacy webhooks, the team realized they were essentially trapped in a manual migration nightmare that threatened to consume months of development time.
Such scenarios illustrate the “vendor hostage crisis” that plagues modern software development, where a single change in a third-party service triggers a domino effect of manual updates and synchronized deployment pipelines. Without a centralized way to manage these external signals, organizations find themselves in a cycle of reactive maintenance, spending more on architectural debt than on new features. The solution lies in shifting away from point-to-point communication toward a more resilient, event-driven framework that treats external data as a generic signal rather than a rigid command.
The High Price of Architectural Rigidity
The hidden costs of a rigid architecture often remain invisible until a major external shift occurs, revealing just how brittle the underlying connections truly are. In many legacy systems, services like order processing, inventory management, and customer notifications are built to listen directly to specific vendor formats, creating a web of dependencies that are nearly impossible to untangle. This lack of a unified communication framework means that any update to an external API requires a coordinated effort across multiple teams, leading to massive technical debt and stalled innovation.
Furthermore, these synchronous API chains create a “scalability wall” where the failure of one service can bring down an entire user journey. If Service A must wait for Service B, which in turn calls Service C, the risk of a timeout or a cascading failure increases exponentially with every added layer. This structural fragility is often the result of prioritizing immediate delivery over long-term integrity, leaving developers with a system that is functional in the short term but prohibitively expensive to evolve as the business grows.
Why the Event-Driven Transition Matters Now
Transitioning to an event-driven architecture is no longer just a luxury for high-scale tech giants; it is a fundamental requirement for survival in a volatile digital economy. In a world where service boundaries shift rapidly, the ability to decouple components allows a business to remain agile and responsive to market changes without needing to rebuild the entire stack. By moving toward a reactive model, companies can ensure that their roadmap is no longer a hostage to the development cycles of their external providers.
Moreover, the modern demand for real-time data processing means that traditional batch jobs and polling methods are increasingly insufficient. An event-driven approach allows for immediate reactions to user actions, such as fraud detection or personalized marketing, without adding latency to the core transactional flow. This shift enables teams to build “sidecar” features that observe existing data streams, allowing for experimentation and rapid deployment without touching the critical paths of the application.
AWS EventBridge as the Digital Nervous System
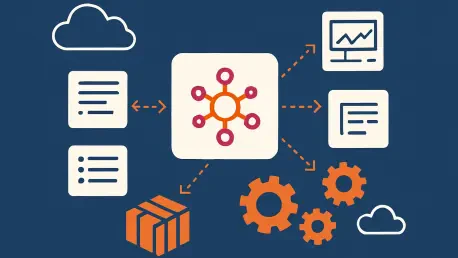
AWS EventBridge serves as the central nervous system for a software ecosystem, shielding the “brain” of the application from the messy details of external stimuli. At the edge of this system, a single Lambda function acts like a reflex center, capturing raw data from vendors and translating it into a standardized internal format before it ever reaches the core services. This “normalization” ensures that downstream microservices only deal with clean, predictable domain events rather than vendor-specific JSON blobs.
The event bus itself acts as the neural pathway, routing information based on predefined rules without the sender ever needing to know who the receiver is. This complete decoupling means that a payment service can emit a “payment.completed” event without caring whether the subscriber is an email notification service, a data warehouse, or a fraud detection engine. By treating the architecture as a living organism with specialized cells, developers can swap out individual components—like moving from Stripe to PayPal—with minimal impact on the rest of the system.
Expert Insights on Architectural Resilience
Architectural maturity is most visible during peak stressors like high-traffic sales events, where the ability to handle spikes determines the difference between profit and loss. Experts emphasize that the true value of EventBridge lies in its “zero-loss” reliability, achieved through the implementation of ubiquitous Dead Letter Queues. If a specific service fails during a traffic surge, the event is not lost to the void; instead, it is preserved in a queue, allowing the team to replay the transaction once the system stabilizes.
Another transformative feature is the “time machine effect” provided by strategic event archiving. By maintaining an audit trail of financial and operational events, teams can re-run historical data to resolve disputes or debug complex state issues that occurred weeks prior. This capability not only improves transparency but also provides a low-cost insurance policy against data corruption. Consequently, organizational autonomy increases, as different departments can subscribe to the same event stream to build their own tools without requiring cross-team meetings or resource-heavy integrations.
Practical Framework for Implementation
Successfully modernizing an architecture requires a systematic focus on standardization and versioning to ensure long-term financial health. Using JSON Schema to validate data at the entry point prevents “poison pill” events from entering the nervous system and causing downstream failures. Furthermore, enforcing proactive versioning within every event payload allows services to migrate to new data formats on their own schedules, eliminating the need for high-risk, synchronized “big bang” deployments.
Optimization should also extend to cost management, where the low operational fees of EventBridge—often pennies per million events—are overshadowed by the massive savings in “cost avoidance.” By reducing the need for expensive NAT gateway charges and inter-service API calls, a well-implemented event bus pays for itself many times over. However, developers must evaluate their specific use case carefully; while this complexity is ideal for systems with shifting service boundaries, simpler monolithic systems may find the additional overhead unnecessary.
The transition toward a centralized event bus proved to be the turning point for organizations seeking to escape the trap of legacy maintenance. By treating every system interaction as a discrete, normalized event, engineering teams transformed their brittle “spaghetti” code into a flexible, reflexive infrastructure capable of adapting to any external change. This architectural evolution allowed companies to redirect their budgets from expensive emergency migrations toward actual product innovation, ensuring that the software remained an asset rather than a liability. Leaders who prioritized these long-term structural improvements discovered that the ability to pivot quickly was the ultimate competitive advantage in an unpredictable market. Moving forward, the focus shifted to refining these event schemas and expanding the use of serverless triggers to further reduce operational overhead and increase system resilience.







