
Support Vector Machines (SVMs) stand as a formidable tool in the realm of machine learning, capable of tackling intricate classification challenges with remarkable precision. Consider a scenario where a developer is tasked with building a model to detect fraudulent transactions in a vast dataset of financial records, where the stakes are high and errors are costly. This guide aims to equip developers with the skills to harness the power of SVMs using Python, specifically through the Scikit-learn library, to create high-performing classifiers. By following this step-by-step tutorial, readers will learn to preprocess data effectively, construct robust training pipelines, fine-tune critical hyperparameters, and evaluate model performance with precision metrics.
The significance of mastering SVMs lies in their ability to handle both linear and non-linear data separation tasks, making them indispensable for a variety of applications ranging from image recognition to bioinformatics. Developers often encounter datasets that defy simple decision boundaries, and SVMs offer a unique solution by maximizing margins and employing kernel tricks to transform data into higher dimensions. This guide provides a practical pathway to understanding and implementing these concepts, ensuring that even complex problems can be addressed with confidence and technical prowess.
By diving into this comprehensive tutorial, developers will gain actionable insights into building SVM classifiers that are not only functional but also optimized for real-world performance. The focus will be on practical implementation, breaking down each phase of the process into manageable steps supported by clear code examples. Whether the goal is to enhance predictive modeling skills or to solve specific industry challenges, this guide serves as a critical resource for elevating machine learning expertise through SVMs.
Unveiling the Power of SVMs: Why Every Developer Should Learn Them
Support Vector Machines have long been recognized as a cornerstone of supervised machine learning due to their exceptional ability to manage a wide array of tasks, including classification, regression, and outlier detection. Their strength lies in delivering high accuracy with minimal manual tuning, often outperforming other algorithms in scenarios where clear decision boundaries are essential. For developers, understanding SVMs opens doors to solving complex data-driven problems with a reliable and mathematically grounded approach.
The appeal of SVMs extends beyond their technical capabilities; they provide a framework that is both intuitive and adaptable to various domains. From distinguishing spam emails to identifying patterns in medical data, the applications are vast and impactful. This guide is designed to take developers through a hands-on journey of building a robust SVM classifier using Python’s Scikit-learn library, ensuring a deep dive into data preparation, model training, hyperparameter tuning, and thorough evaluation.
Ultimately, learning SVMs equips developers with a powerful toolset to tackle predictive modeling challenges with precision. The focus here will be on practical implementation, ensuring that each step is accessible and directly applicable to real-world projects. By mastering these techniques, developers can confidently integrate SVMs into their machine learning repertoire, enhancing their ability to deliver impactful solutions.
The Evolution and Importance of SVMs in Machine Learning
Tracing the trajectory of Support Vector Machines reveals their emergence as a pivotal algorithm in the machine learning domain since their introduction in the 1990s. Developed as a method to address complex classification problems, SVMs quickly gained prominence for their ability to handle datasets where traditional linear models fell short. Their historical significance is marked by a consistent track record of success in diverse fields, establishing them as a reliable choice for developers seeking effective solutions.
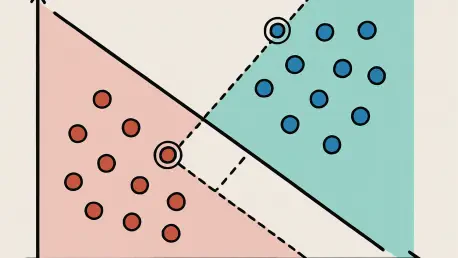
The enduring relevance of SVMs in today’s machine learning landscape is rooted in their unique approach to maximizing the margin between data classes, ensuring optimal separation even in challenging scenarios. Unlike many algorithms that struggle with overfitting, SVMs strike a balance by focusing on support vectors—key data points that define the decision boundary. This methodology, combined with the innovative kernel trick, allows SVMs to transform non-linear problems into solvable linear ones, maintaining their edge in precision-driven tasks.
For developers aiming to achieve high accuracy in predictive modeling, Support Vector Machines (SVMs) remain an essential tool due to their robustness and adaptability. Their capacity to handle high-dimensional data and create clear decision boundaries makes them particularly valuable in applications requiring meticulous analysis. As machine learning continues to evolve, the foundational principles of SVMs provide a critical understanding that complements newer methodologies, ensuring developers are well-equipped for current and emerging challenges.
Building a High-Performance SVM Classifier: Step-by-Step in Python
Creating an effective SVM classifier requires a structured approach that addresses every aspect of the machine learning workflow. This section guides developers through the essential phases of building a high-performance model using Python and Scikit-learn, ensuring each step is clear and actionable. From data preparation to evaluation, the process is broken down into detailed instructions accompanied by code snippets for practical implementation.
The journey begins with understanding the importance of preprocessing and extends to constructing efficient pipelines that prevent common pitfalls. Subsequent steps focus on tuning hyperparameters to optimize model behavior and evaluating performance with industry-standard metrics. Each phase is crafted to provide developers with the knowledge and tools needed to deploy SVM classifiers that meet rigorous performance standards.
By following these steps, developers can transform raw data into a finely tuned predictive model ready for real-world application. The emphasis on practical coding ensures that theoretical concepts are immediately applicable, bridging the gap between understanding and execution. This comprehensive guide aims to empower developers to build SVM models with confidence and precision.
Step 1: Preprocessing Data for Optimal SVM Performance
Data preprocessing forms the bedrock of any successful SVM implementation, as these models are highly sensitive to the scale of input features. Without proper preparation, features with larger numerical ranges can disproportionately influence the model, leading to skewed results and poor performance. This step underscores the necessity of transforming data to ensure balanced distance calculations, a critical factor in achieving accurate classifications.
Understanding Feature Scaling: Why It’s a Must
Feature scaling, particularly through standardization, is a non-negotiable requirement when working with SVMs due to their reliance on geometric distances. Standardization adjusts the data to have a mean of 0 and a standard deviation of 1, often referred to as Z-score normalization. This process ensures that no single feature dominates the model’s decision-making process, allowing for a fair contribution from all variables in determining the optimal hyperplane.
The impact of neglecting scaling can be profound, as unscaled data disrupts the margin maximization process central to SVM functionality, which is crucial for accurate predictions. Developers must apply scaling consistently across training and testing datasets to maintain model integrity. This foundational step sets the stage for all subsequent processes, ensuring that the SVM operates on a level playing field where every feature is equally represented.
Creating Sample Data for Hands-On Learning
To facilitate practical learning, developers can generate a synthetic dataset using Scikit-learn’s make_classification function, which creates a balanced set of data points for binary classification. This dataset typically includes 100 samples with 2 informative features, providing a manageable yet illustrative example to work through the SVM pipeline. Such an approach allows for experimentation without the complexity of real-world data nuances.
Alternatively, publicly available datasets like the Iris dataset can be used for those preferring a more realistic context. The key is to select or create data that clearly demonstrates the separation of classes, making it easier to visualize the effects of SVM decision boundaries. This hands-on preparation ensures developers can follow along with code examples and observe the immediate impact of each processing step.
Step 2: Constructing a Seamless Preprocessing and Training Pipeline
Integrating preprocessing and training into a single workflow is essential for maintaining data integrity and efficiency in SVM model development, and Scikit-learn offers a powerful solution to achieve this. Its Pipeline class chains multiple steps together, ensuring that transformations like scaling are applied correctly across training and testing phases. This approach simplifies the process and safeguards against common errors that can compromise model validity.
Preventing Data Leakage with Pipelines
Data leakage poses a significant risk when preprocessing steps inadvertently incorporate information from the test set into the training process, leading to overly optimistic performance estimates. Pipelines mitigate this by fitting transformations, such as StandardScaler, solely on the training data and applying them consistently to the test data. This separation preserves the model’s ability to generalize to unseen data, a crucial aspect of reliable machine learning.
Understanding the mechanics of pipelines helps developers avoid subtle mistakes that can undermine months of work, ensuring that every step in the process is executed with precision. By encapsulating preprocessing and modeling steps within a single object, pipelines ensure repeatability and clarity in the workflow. This structured methodology is particularly valuable when scaling projects or collaborating with teams, as it standardizes the process across different environments.
Setting Up Your First SVM Pipeline
Building a basic SVM pipeline involves combining StandardScaler and the SVC (Support Vector Classifier) from Scikit-learn into a cohesive unit, ensuring that the process of data preprocessing and model training is streamlined and efficient. The code for this setup might look like: from sklearn.pipeline import Pipeline; from sklearn.preprocessing import StandardScaler; from sklearn.svm import SVC; pipeline = Pipeline([(‘scaler’, StandardScaler()), (‘svm’, SVC())]). This configuration automates the scaling of features before passing them to the SVM for training.
Once the pipeline is defined, it can be fitted to the training data using a simple command, ensuring that scaling and training occur in the correct sequence. Developers can then use this pipeline to make predictions on new data, confident that the preprocessing steps are applied consistently. This streamlined approach not only saves time but also enhances the reliability of the resulting model.
Step 3: Fine-Tuning Hyperparameters for Maximum Accuracy
Hyperparameter tuning is a pivotal step in optimizing an SVM classifier, as default settings rarely yield the best performance for specific datasets. Parameters like C and gamma directly influence the model’s behavior, affecting the balance between simplicity and complexity in decision boundaries. This section explores their roles and provides a systematic method for finding the optimal values to enhance accuracy.
Decoding C: Balancing Margin and Misclassification
The parameter C in SVMs governs the trade-off between achieving a wide margin and minimizing misclassifications on the training data. A low C value prioritizes a softer margin, allowing some errors to create a simpler, more generalizable model, which can help prevent overfitting. Conversely, a high C value pushes for a harder margin, striving to classify all training points correctly, which may result in a complex model prone to overfitting.
Understanding the impact of C requires careful consideration of the dataset’s characteristics and the desired outcome. For datasets with significant noise, a lower C might be preferable to avoid capturing irrelevant patterns. Developers must experiment with different values to strike the right balance, ensuring the model neither underfits nor overfits the training data.
Unpacking GammControlling Decision Boundary Complexity
Gamma, a parameter specific to kernel functions like the Radial Basis Function (RBF), determines the influence radius of individual support vectors in shaping the decision boundary. A low gamma value results in a broader influence, leading to smoother boundaries that might underfit the data. In contrast, a high gamma value restricts influence to a smaller area, creating intricate boundaries that risk overfitting by capturing noise.
The choice of gamma significantly alters how the SVM interprets the data’s structure, making it a critical factor in model performance. Developers should assess the complexity of their dataset when selecting gamma, as highly non-linear data might benefit from a higher value, while simpler patterns could require a lower setting. This nuanced adjustment is key to crafting a model that accurately reflects underlying trends.
Leveraging GridSearchCV for Optimal Settings
To systematically identify the best combination of C and gamma, Scikit-learn’s GridSearchCV offers a powerful tool for hyperparameter optimization, making it easier to fine-tune machine learning models. An example implementation could be: from sklearn.model_selection import GridSearchCV; param_grid = {‘svm__C’: [0.1, 1, 10], ‘svm__gamma’: [0.01, 0.1, 1]}; grid_search = GridSearchCV(pipeline, param_grid, cv=5). This code tests various combinations across a cross-validation framework to determine the most effective settings.
Running GridSearchCV provides insights into which parameters yield the highest cross-validation scores, guiding developers toward optimal configurations for their models. The process, while computationally intensive, is indispensable for fine-tuning SVMs to specific tasks. By automating the search, developers can focus on interpreting results rather than manually adjusting values, ensuring efficiency and accuracy in model optimization.
Step 4: Evaluating Model Performance with Precision Metrics
Assessing the performance of a tuned SVM model is crucial to understanding its effectiveness on unseen data and ensuring it meets project requirements. This step involves deploying a range of evaluation tools to measure how well the classifier distinguishes between classes. A thorough evaluation provides confidence in the model’s predictive capabilities and highlights areas for potential improvement.
Breaking Down the Confusion Matrix
The confusion matrix serves as a fundamental tool for dissecting a classifier’s performance by categorizing predictions into true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN). These components reveal the model’s accuracy in identifying correct and incorrect classifications across classes. Metrics derived from this matrix, such as precision (TP / (TP + FP)), recall (TP / (TP + FN)), and F1-score (the harmonic mean of precision and recall), offer a comprehensive view of performance.
Interpreting the confusion matrix allows developers to pinpoint specific weaknesses, such as a tendency to misclassify one class over another. This detailed breakdown is essential for applications where certain types of errors, like false negatives in medical diagnostics, carry higher consequences. Utilizing these metrics ensures a nuanced understanding of the model’s strengths and limitations beyond simple accuracy scores.
Visualizing Success with ROC Curve and AUC Score
The Receiver Operating Characteristic (ROC) curve and the Area Under the Curve (AUC) score provide vital insights into a classifier’s ability to discriminate between classes. The ROC curve plots the true positive rate against the false positive rate across various decision thresholds, with an ideal curve bending sharply toward the top-left corner. The AUC score summarizes this curve into a single value, where 1.0 indicates perfect discrimination and 0.5 suggests performance no better than random guessing.
Generating an ROC curve in Python can be achieved with the following code: from sklearn.metrics import roc_curve, auc; import matplotlib.pyplot as plt; fpr, tpr, _ = roc_curve(y_test, y_pred_proba); roc_auc = auc(fpr, tpr); plt.plot(fpr, tpr, label=f’AUC = {roc_auc:.2f}’). This visualization helps developers assess the trade-offs between sensitivity and specificity at different thresholds. Such tools are indispensable for validating the model’s robustness, particularly in imbalanced datasets where other metrics might be misleading.
Key Takeaways: Your SVM Mastery Checklist
- Always scale features using standardization to ensure balanced distance calculations, which are critical for SVM accuracy.
- Use pipelines to prevent data leakage and streamline preprocessing and training workflows for consistency.
- Tune hyperparameters C and gamma with GridSearchCV to achieve optimal model performance tailored to specific datasets.
- Evaluate models thoroughly using confusion matrix, precision, recall, F1-score, and ROC-AUC metrics to gain a complete picture of effectiveness.
Beyond the Basics: Applying SVMs to Real-World Challenges
The skills acquired through this guide lay a strong foundation for tackling real-world problems where SVMs excel, such as fraud detection in financial systems. By identifying unusual patterns in transaction data, SVMs can flag potential fraud with high accuracy, protecting businesses from significant losses. Developers can apply the preprocessing and tuning techniques learned to customize models for such high-stakes environments, ensuring reliability under pressure.
Another promising application lies in image classification, where SVMs can distinguish between categories like handwritten digits or medical imaging anomalies. Their ability to handle high-dimensional data through kernel tricks makes them suitable for processing pixel-based inputs effectively. Experimenting with different kernels and parameters allows developers to adapt SVMs to the unique challenges of visual data, enhancing their versatility across domains.
Looking ahead, integrating SVMs with emerging trends like deep learning offers exciting possibilities for hybrid models that combine the strengths of both approaches. Addressing challenges such as imbalanced datasets through techniques like SMOTE (Synthetic Minority Oversampling Technique) further extends their utility. Developers are encouraged to explore these advanced applications, pushing the boundaries of what SVMs can achieve in diverse and complex scenarios.
Wrapping Up: Elevate Your Machine Learning Skills with SVMs
Reflecting on the journey through this guide, developers navigated the intricacies of Support Vector Machines from foundational concepts to crafting a production-ready classifier. Each step, from meticulous data preprocessing to hyperparameter optimization, was thoroughly covered to ensure a robust understanding and application. The hands-on approach with Python’s Scikit-learn library provided practical experience that solidified theoretical knowledge.
As a next step, developers should consider diving into varied datasets to test the adaptability of SVMs across different problem spaces. Experimenting with alternative kernels beyond RBF, such as linear or polynomial, could uncover new performance benchmarks for specific tasks. Continuous learning through such exploration is key to deepening expertise in this powerful algorithm.
Lastly, applying these skills to personal or professional projects offers a pathway to refine techniques and address unique challenges. Sharing outcomes or engaging with broader machine learning communities can foster collaborative growth and innovation. This progression marks a significant advancement in machine learning capabilities, paving the way for tackling even more sophisticated predictive modeling endeavors.







