
Imagine a tech enterprise struggling to keep up with the explosive demand for AI-driven services like chatbots and intelligent search systems, only to find their isolated large language model (LLM) deployments buckling under inefficient resource use and skyrocketing costs. This scenario is all too common in today’s fast-paced digital landscape, where the need for scalable, high-performance AI infrastructure has never been more pressing. The fusion of vLLM, a high-throughput LLM serving engine, with Kubernetes, a powerful orchestration platform, offers a transformative solution to these challenges by centralizing resources and optimizing GPU utilization.
The purpose of this guide is to provide a comprehensive roadmap for deploying a centralized vLLM setup on Kubernetes, enabling organizations to build a robust and scalable AI ecosystem. By following the detailed steps and strategies outlined, readers will learn how to streamline their AI operations, reduce operational overhead, and ensure seamless integration across multiple applications. This approach not only addresses current inefficiencies but also positions enterprises to adapt to future demands in the rapidly evolving AI domain.
The significance of this combination cannot be overstated, as it tackles the critical pain points of resource waste and scaling limitations head-on. Efficient GPU utilization through vLLM, paired with Kubernetes’ ability to manage complex deployments, creates a production-ready environment capable of supporting diverse AI workloads. This guide aims to equip technical teams with the knowledge to harness these technologies, paving the way for innovation and cost savings in their infrastructure.
Unleashing AI Potential with Centralized vLLM and Kubernetes
The integration of vLLM’s high-performance capabilities with Kubernetes’ orchestration prowess marks a significant leap forward in building scalable AI infrastructure that can adapt to growing demands. vLLM is renowned for delivering exceptional throughput, often surpassing traditional LLM serving systems by a wide margin, primarily through its optimized GPU handling. When coupled with Kubernetes, which excels in managing containerized workloads across clusters, this combination ensures that AI models are deployed efficiently, maximizing resource use while maintaining reliability.
This approach is particularly vital for enterprises aiming to deploy production-ready LLMs at scale, ensuring efficiency and consistency across operations. Centralized management of vLLM instances on Kubernetes eliminates the pitfalls of fragmented deployments, such as inconsistent performance and wasted computational power. It allows organizations to support a variety of applications—from customer support bots to advanced search algorithms—under a unified, streamlined infrastructure that adapts dynamically to workload demands.
Beyond immediate operational benefits, this strategy offers a glimpse into a future-proof AI ecosystem that can adapt to evolving technological demands. By leveraging Kubernetes’ robust tools for scheduling, scaling, and monitoring, alongside vLLM’s processing efficiency, businesses can achieve not only cost-effective solutions but also the agility needed to stay competitive. The following sections will delve into the specific advantages, practical deployment steps, and long-term implications of adopting this powerful synergy.
Why Centralized vLLM Matters in AI Operations
Managing multiple vLLM instances across various production services poses significant challenges, often leading to operational bottlenecks. Isolated deployments, where each application runs its own vLLM instance, create a tight coupling that hinders independent scaling of services. This setup results in inefficiencies, as applications cannot dynamically adjust to traffic spikes without over-provisioning resources, ultimately impacting performance and user experience.
Furthermore, such fragmented approaches lead to substantial resource waste and escalated costs. Allocating dedicated GPUs to individual applications means that during low-traffic periods, expensive hardware remains idle, draining budgets without delivering value. The operational overhead of maintaining separate vLLM setups for each service adds another layer of complexity, requiring teams to juggle multiple configurations, updates, and monitoring tasks, which can strain technical resources.
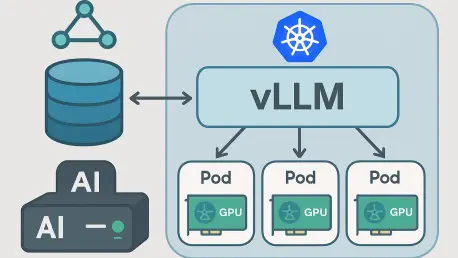
In contrast, a centralized vLLM service hosted on Kubernetes addresses these drawbacks by providing a unified inference endpoint for diverse applications. This model ensures optimal GPU utilization across the board, reduces costs by sharing resources, and simplifies management through a single, cohesive infrastructure. For industries relying on AI-driven tools like chatbots or search engines, this shift to centralization is not just a convenience but a strategic necessity to maintain efficiency and competitiveness.
Harnessing Kubernetes for vLLM Deployment Advantages
Kubernetes stands out as an ideal platform for hosting centralized vLLM setups due to its advanced orchestration features tailored for production environments. Its ability to manage containerized workloads across clusters ensures that AI inference services operate seamlessly, even under varying loads. This section explores how specific Kubernetes capabilities enhance vLLM deployments, addressing critical needs like resource optimization and service reliability.
The platform’s flexibility in handling complex deployments makes it a natural fit for AI infrastructure demands, ensuring efficient management of resources. From scheduling workloads on appropriate hardware to balancing traffic across replicas, Kubernetes provides a robust foundation that minimizes downtime and maximizes throughput. These features collectively enable organizations to deploy vLLM in a way that supports multiple applications without compromising on performance or cost efficiency.
Resource Allocation with Node Selectors and Affinity
Kubernetes offers powerful mechanisms like node selectors, taints, tolerations, and affinity labels to ensure precise scheduling of vLLM pods on GPU-enabled nodes. By designating specific nodes for GPU workloads, these tools prevent the wasteful allocation of expensive resources to applications that only require CPU power. This targeted scheduling is crucial for maintaining an efficient balance between cost and performance in AI deployments.
Additionally, affinity rules allow for fine-tuned control over pod placement, ensuring that vLLM instances are colocated with compatible hardware while avoiding contention with other workloads. Taints and tolerations further refine this process by restricting certain nodes to specific pods, guaranteeing that GPU resources are reserved for inference tasks. This strategic allocation optimizes the use of hardware, reducing idle time and enhancing overall system throughput.
GPU Integration with Device Plugins
Device plugins play a pivotal role in Kubernetes by advertising GPU availability on cluster nodes, enabling the scheduler to place vLLM pods on the correct hardware. These plugins communicate real-time resource status, ensuring that the system remains aware of GPU capacity and can make informed scheduling decisions. This integration is essential for avoiding resource conflicts and maximizing hardware efficiency.
Without such plugins, Kubernetes would lack visibility into specialized resources like GPUs, potentially leading to suboptimal pod placement. By bridging this gap, device plugins ensure that vLLM workloads are consistently assigned to nodes equipped to handle their intensive computational demands. This results in smoother operations and a significant boost in inference performance across the cluster.
Ensuring Reliability with Service Lifecycle Management
Kubernetes enhances service reliability through continuous health and readiness checks, monitoring the status of vLLM pods at regular intervals to ensure optimal performance. If a pod fails or becomes unresponsive, the deployment controller automatically replaces it with a new instance, maintaining the desired scale and minimizing service disruptions. This self-healing capability is indispensable for production environments where uptime is critical.
Moreover, these lifecycle management features ensure that applications relying on vLLM face no interruptions in inference capabilities. By automating recovery processes, Kubernetes reduces the need for manual intervention, allowing technical teams to focus on innovation rather than troubleshooting. This reliability forms the backbone of a stable AI infrastructure capable of handling real-world demands.
Optimizing Traffic with Load Balancing
Deploying multiple replicas of vLLM pods behind a load balancer in Kubernetes ensures balanced traffic distribution across applications. This setup prevents any single pod from becoming a bottleneck, enhancing overall performance and availability for services accessing the inference endpoint. Load balancing is a key factor in achieving consistent response times under varying workloads.
Additionally, this configuration allows for efficient resource utilization by dynamically routing requests to the least burdened replicas. It supports high availability by redirecting traffic away from failed or overloaded pods, ensuring continuous service delivery. Such optimization is vital for organizations running multiple AI-driven applications that share the same centralized vLLM infrastructure.
Step-by-Step Guide to Deploying vLLM on Kubernetes
This section provides a detailed, actionable guide to setting up a centralized vLLM deployment on a Kubernetes cluster, using a practical example of a 5-node cluster with GPU-enabled nodes. The steps are designed to offer clarity and hands-on insight for technical teams looking to implement this solution. By following this walkthrough, organizations can establish a scalable AI inference service tailored to their needs.
Each step addresses a specific aspect of the deployment process, from cluster setup to application integration, ensuring a comprehensive understanding of the workflow. The guide assumes a basic familiarity with Kubernetes concepts but breaks down complex configurations into manageable tasks. The goal is to enable readers to replicate this setup in their environments with confidence.
Step 1: Setting Up the Kubernetes Cluster Environment
Begin by creating a 5-node Kubernetes cluster divided into separate CPU and GPU node pools, with three nodes dedicated to CPU workloads and two equipped with NVIDIA #00 GPUs to ensure optimal performance. This segregation ensures that resource-intensive vLLM pods are scheduled on appropriate hardware, maximizing efficiency. Verify GPU resource availability on the designated nodes using the command kubectl describe node to confirm that the cluster recognizes the specialized hardware.
Ensure that the cluster is configured to handle the specific requirements of AI workloads, such as sufficient memory and network bandwidth for GPU nodes. Checking node status early in the process helps identify any discrepancies in resource allocation before proceeding with deployment. This foundational step sets the stage for a smooth integration of vLLM into the Kubernetes environment.
Pre-Installed Device Plugins on DigitalOcean
Certain platforms, such as DigitalOcean, come with pre-installed GPU device plugins, simplifying the setup process by automatically advertising GPU resources to the Kubernetes scheduler. For clusters hosted on other providers or on-premises, manual installation of the NVIDIA device plugin may be necessary to achieve similar functionality. Refer to the official Kubernetes documentation for guidance on installing and configuring these plugins if they are not pre-installed.
Confirming the presence and operation of device plugins is a critical task, as they ensure accurate resource reporting within the cluster. Without this visibility, pods risk being scheduled on incompatible nodes, leading to performance issues. Taking the time to validate this setup prevents downstream complications during vLLM deployment.
Step 2: Configuring the vLLM Deployment Manifest
Define the vLLM deployment manifest by specifying the desired model, such as “meta-llama/Llama-3.1-8B,” along with resource requests for CPU, memory, and GPU to ensure optimal performance. Include configurations for gated models by creating Kubernetes secrets to store access tokens, like those required for Hugging Face models, and reference these secrets in the deployment spec. This ensures secure access to restricted models while maintaining compliance with licensing requirements.
Tailor the manifest to include parameters for replicas, ideally matching the number of GPU nodes for optimal load distribution. For a two-node GPU setup, deploy two replicas to utilize both resources effectively while ensuring high availability. Carefully crafting this manifest is essential for aligning the deployment with hardware capabilities and organizational needs.
Memory Requirements for Large Models
Large language models have significant memory demands, often requiring substantial GPU memory for loading model weights, with additional overhead for operational tasks. For instance, the Llama-3.1-8B model needs approximately 16GB for weights alone, necessitating careful adjustment of memory requests and limits in the manifest. Underestimating these requirements can lead to pod crashes or suboptimal performance.
Regularly assess the memory footprint of chosen models to avoid resource contention within the cluster. Adjusting limits based on real-world usage data ensures that vLLM pods operate efficiently without overloading nodes. This proactive approach to resource planning is key to sustaining long-term deployment stability.
Step 3: Scheduling Pods with Tolerations and Node Selectors
Incorporate tolerations and node selectors into the deployment specification to ensure that vLLM pods are scheduled exclusively on GPU nodes. Tolerations allow pods to be placed on nodes with specific taints, while node selectors restrict placement to nodes with matching labels, guaranteeing precise hardware targeting. This configuration is essential for preventing resource mismatches during scheduling.
Deploying multiple replicas with these settings also facilitates load distribution and enhances fault tolerance across GPU nodes. By spreading workloads evenly, the cluster can handle traffic surges without overloading individual nodes, ensuring stability during high-demand periods. This step is a cornerstone of achieving both efficiency and resilience in AI inference services.
Importance of Taint and Label Matching
Matching taints and labels on GPU nodes is critical for accurate pod placement, ensuring that only vLLM workloads access specialized hardware. A mismatch can result in pods being scheduled on unsuitable nodes, leading to performance degradation or deployment failures. Verifying these configurations in the manifest prevents such issues from arising.
This precise alignment of taints, tolerations, and labels optimizes resource efficiency by reserving GPU capacity for inference tasks, while also minimizing the risk of contention with other cluster workloads and maintaining a clear separation of responsibilities. Such attention to detail during setup pays dividends in operational smoothness.
Step 4: Creating a Service for Internal Traffic Routing
Set up a Kubernetes service to route internal traffic to vLLM pods by defining a service manifest that targets the deployment’s pod labels. Apply this manifest using kubectl apply -f manifests.yaml to create the necessary resources, and monitor pod readiness through logs to confirm successful initialization. This service acts as the gateway for applications to access inference capabilities.
Ensuring that the service is correctly configured prevents connectivity issues between applications and vLLM pods, while regularly checking logs during this phase helps identify any startup delays or errors in model loading. A well-defined service is indispensable for maintaining seamless communication within the cluster.
Testing Deployment with Port Forwarding
Use kubectl port-forward service/llama-3 8080:80 to test the vLLM deployment locally, allowing direct querying of the service to validate its responsiveness. This temporary access method helps confirm that the deployment is functioning as expected before integrating it with production applications. Testing at this stage mitigates the risk of downstream integration failures.
Analyzing the responses from port-forwarded queries provides insight into the service’s performance and accuracy. Any anomalies detected during testing can be addressed promptly, ensuring that the vLLM setup meets operational standards. This validation step builds confidence in the deployment’s readiness for broader use.
Step 5: Enabling Application Access to Centralized vLLM
Configure applications within the cluster to connect to the vLLM inference service via an internal endpoint, such as https://llama-3.default.svc.cluster.local/v1/completions. This endpoint supports OpenAI-compatible requests, allowing diverse services to leverage centralized GPU resources without requiring individual vLLM instances. Establishing this connection is the final piece of the integration puzzle.
Ensure that application configurations point to this internal service name for consistent access across the cluster. Verifying connectivity and request handling during initial integration helps iron out any network or compatibility issues. This setup enables a cohesive AI infrastructure that serves multiple use cases efficiently.
Benefits of Shared Inference Infrastructure
A centralized endpoint for vLLM inference allows multiple applications to share high-performance GPU resources, significantly reducing the need for redundant deployments. This shared infrastructure lowers costs by consolidating hardware usage, ensuring that GPUs are utilized to their fullest potential. The approach streamlines resource management across the organization.
Moreover, this model simplifies updates and maintenance, as changes to the vLLM setup can be applied centrally without affecting individual applications. It fosters scalability by accommodating new services without additional overhead. Such benefits underscore the value of centralization in modern AI operations.
Key Takeaways from Centralized vLLM Deployment
The deployment of vLLM on Kubernetes offers a transformative approach to AI infrastructure by addressing inefficiencies inherent in isolated setups. Centralization eliminates resource waste, cuts down on costs, and reduces operational complexity through a unified service model. This shift is essential for organizations managing multiple AI-driven applications.
Kubernetes enhances this setup with precise GPU scheduling through node selectors, tolerations, and device plugins, ensuring optimal hardware use. Its load balancing and lifecycle management features maintain reliability and scalability under varying demands. These capabilities form the backbone of a resilient inference system.
Applications benefit immensely from accessing a shared inference endpoint, maximizing GPU utilization without the burden of individual vLLM instances. The practical steps of configuring manifests, verifying resources, and testing connectivity provide a clear path to implementation, ensuring that users can seamlessly adopt this approach for optimal performance. These takeaways highlight the efficiency and adaptability of this architecture.
Future Implications for AI Infrastructure Scalability
Centralized vLLM on Kubernetes aligns with the growing industry trend toward cost-effective, scalable LLM solutions that can handle diverse workloads. As AI adoption accelerates, the demand for infrastructure that can dynamically adjust to usage patterns becomes paramount, ensuring that resources are utilized efficiently. This approach positions organizations to meet these needs with agility and precision.
Looking ahead, advancements such as sophisticated autoscaling policies could further optimize resource allocation by responding to real-time traffic fluctuations. Integration with edge computing might also emerge as a key focus, bringing inference closer to end-users for reduced latency. These potential developments promise to enhance the flexibility of centralized deployments.
Challenges like managing multi-tenant environments or adapting to evolving hardware requirements will need careful consideration, and organizations must stay proactive in addressing these complexities to maintain a competitive edge. Exploring how this model can evolve to fit specific operational contexts ensures long-term relevance in the AI landscape.
Building Your Scalable AI Future with vLLM and Kubernetes
Reflecting on the journey of deploying centralized vLLM on Kubernetes, the process proved to be a game-changer in achieving a production-ready AI infrastructure. The meticulous steps taken—from setting up the cluster to integrating applications—ensured that resources were harnessed efficiently, paving the way for operational excellence. This implementation marked a significant stride toward scalability and reliability.
As a next step, starting with a small test cluster to validate configurations before full-scale deployment is highly recommended, and monitoring resource usage closely provides valuable insights that inform iterative improvements tailored to specific application demands. This gradual approach minimizes risks and maximizes the learning curve during rollout.
Exploring further optimizations, such as fine-tuning autoscaling parameters or integrating advanced monitoring tools, can significantly elevate the infrastructure’s performance. Technical teams are encouraged to experiment with these enhancements to uncover additional efficiencies, ensuring that the system operates at its peak. Embracing this continuous improvement mindset promises to drive sustained AI innovation within any organization.







